Document Upload Architecture
Sequence Diagram with NOS_OCR
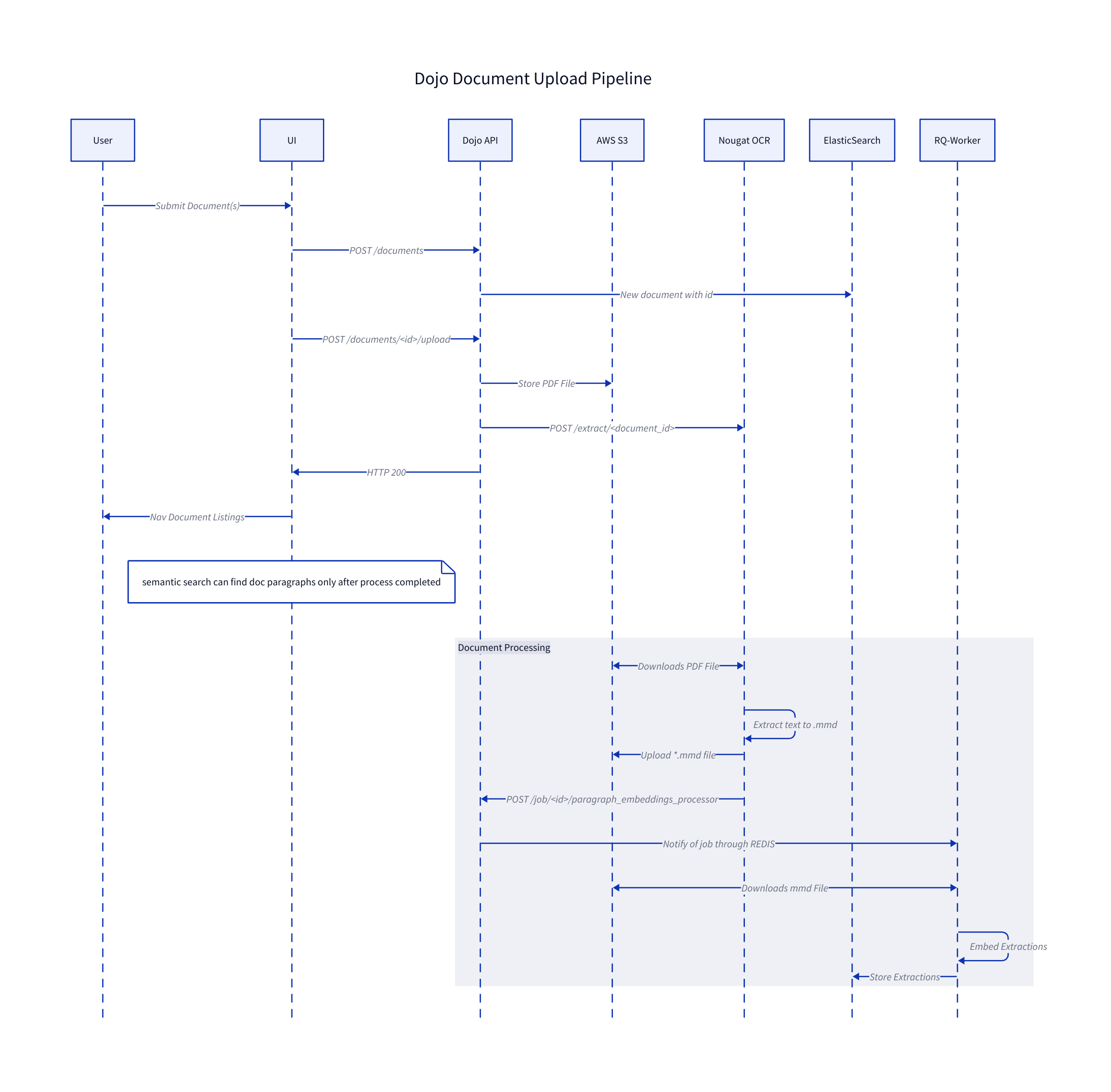
Relevant Services:
- Dojo UI
- Dojo API
- Dojo Queue System and RQWorker(tasks)
- Jataware's external NOS_OCR, nougat-ocr [as a] service
- Elasticsearch
- AWS S3
UI Details
Documents can be uploaded by users through a drag-and-drop (or click and browse to file) interface on the Dojo UI.
The UI route for the Document Explorer Upload functionality is under /documents/upload.
See the source code:
ui/client/documents/upload/index.js
Upon adding the files, filling in the input forms with relevant metadata, and pressing "Upload All", the Dojo UI will first make a request to create a document object to the Dojo API.
The Dojo API will then format and create an elasticsearch document. Once the Dojo UI receives an OK (and the new Document ID) from the API, it will then upload the document to the API using the new ID to associate the file with the metadata.
After the Dojo UI receives an OK from the upload endpoint, it will automatically redirect to the Document Explorer Listings page (UI url /documents).
API Details
On the API side- once the Dojo API receives the upload request, it will first upload it to S3, then make a request to an external (to Dojo) service- NOS_OCR.
NOS_OCR stands for Nougat-Ocr-Service_OCR. Once the request to NOS_OCR/extract/<document_id> is acknowledged, the Dojo UI returns a success response to the client (Dojo UI).
NOS_OCR Text Extractor Details
The NOS_OCR project has both a thing HTTP server with one endpoint (/extract) and a Redis-Queue (RQ), similar to the Dojo stack.
Sample request to NOS_OCR:
POST https://<NOS_OCR_HOST>/extract/<document_id>
{
"s3_url": "s3://<my-bucket>/documents/<guid>/<filename>.pdf",
"callback_url": "https://<DOJO_API_HOST>/job/<document_id>/paragraph_embeddings_processors.calculate_store_embeddings"
}
Upon receiving a request to extract the text, it enqueue the task to an RQ worker (similar to Dojo) and acknowledges the request with a success response (Dojo API in this instance).
Once the task is picked up by a worker, it will:
- Download the document from the S3 bucket/location, and save to a documents_cache folder location.
- Use nougat-ocr to extract the text, which uses a cli interface and requires the file to be on the file system.
- Save the extractions as a .mmd (multi-markdown) file
- Upload the .mmd file to S3, on the same location and as a sibling of the original document
s3://<my-bucket>/documents/<guid>/<filename>.mmd - Make a POST HTTP request back to the
callback_urlparameter, with the following payload data
{
"context": {
"s3_key": <mmd_S3_key>,
"document_id": <document_id>
}
}
RQWorker Details
The callback URL that Dojo API sends to NOS_OCR contains a directive to queue up a new Dojo RQ task, handled by Dojo's RQWorker. This tasks will download the .mmd extractions file into memory, and loop through each line of text:
- Filtering the text that isn't a paragraph (parameters and requirements on the RQWorker code itself)
- Filtering text that is related to citations (eg footnotes and such)
- Embed the text using an online (implemented with openai's gpt4) or offline model (supported, but integration pending).
- Upload each text/embedding pair to elasticsearch into the /document_paragraphs index.
- Update the Document object in elasticsearch with the final
processed_attimestamp.
Once the final RQWorker step is completed (paragraph_embeddings_processors.calculate_store_embeddings task), the document can be considered as processed and can be searched through using the Dojo API's semantic search or Knowledge AI feature.
Without a NOS_OCR+GPU
If OCR_URL is not present on the dojo stack envfile, the above process is simplified to:
Upon uploading a document from UI -> API, the API queues the rqworker task paragraph_embeddings_processor:full_document_process instead of calling the service at OCR url. This rqworker task will download the uploaded PDF, perform the OCR extractions, create the paragraph embeddings, and populate the elasticsearch backend with the resulting paragraphs. This option creates inferior text extractions than the option with NOS_OCR, at a cheaper cost (no need for an external service with a GPU available at all times).