Intro to Dojo
The Dojo Docs are in the process of being updated. Some pages and screenshots may be out of date while we bring them up to speed. Please contact Jataware with any questions that aren't answered here.
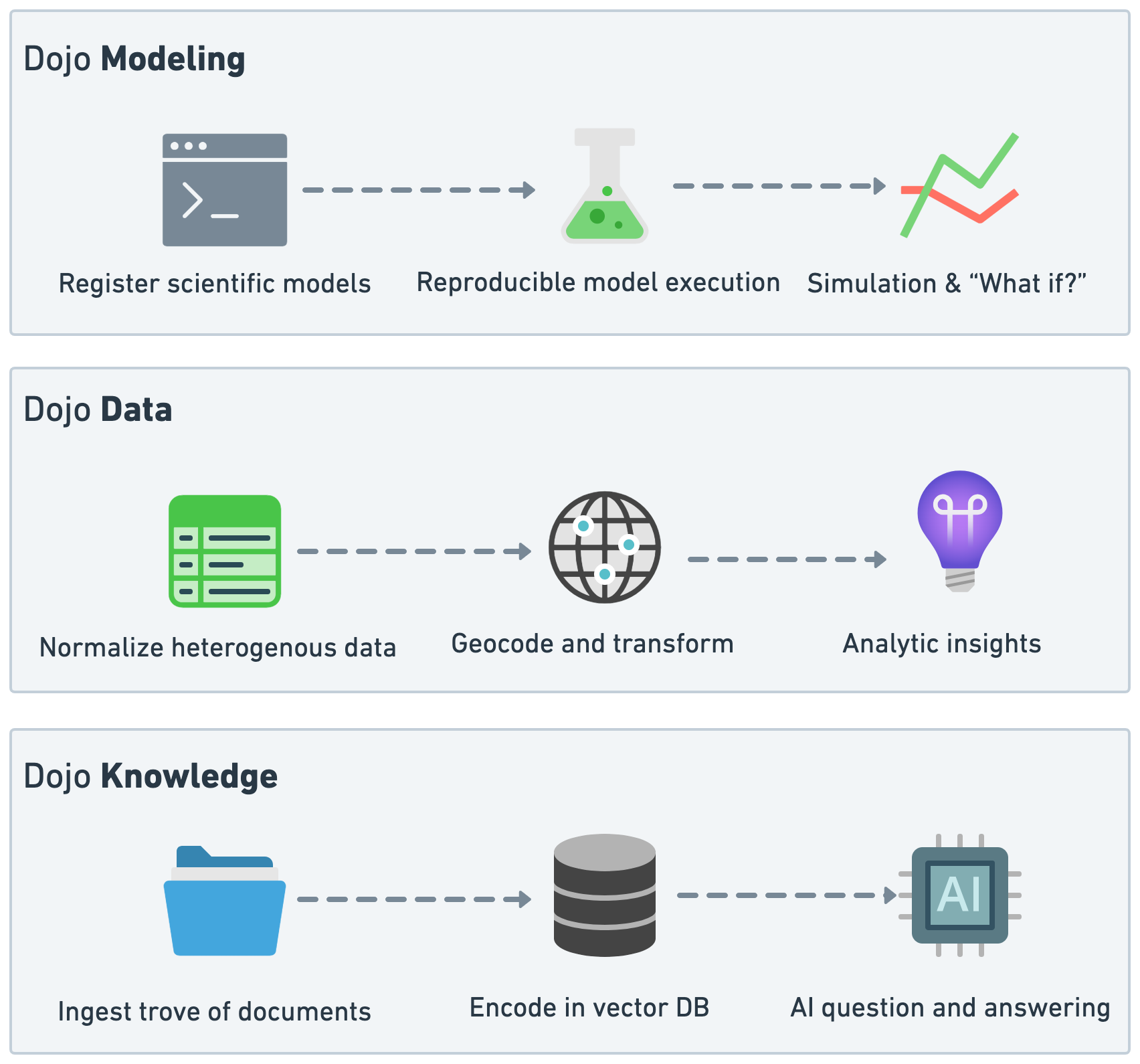
Dojo Overview
Developed by Jataware Corporation under DARPA’s World Modelers program, Dojo offers a unique suite of capabilities that is designed to reduce the gap between scientists and decision makers through three modalities: scientific modeling and simulation, consolidation of heterogeneous data and analysis of documents, reports and briefing material. Dojo has the ability to radically democratize the wisdom of experts and make it available to those who need it most in the policymaking, national security and development sectors. Dojo offers seamless interoperability with Causemos, an analysis interface that allows for the exploration of Dojo models, data and knowledge.
Models in Dojo
The Problem
Scientific models can be written in a wide range of programming languages and structured in an endless diversity of configurations. Running them takes considerable expertise, leaving them difficult to manage without the specific skills of the initial developer. For example, models written in C++ are largely inaccessible to scientists who rely on Python, let alone to analysts with no computer programming expertise.
Dojo's goal is to approach models as executable programs that can be run in any context. Whether a user submits a crop model written in Fortran, such as DSSAT, a locust hopper presence prediction model written in R or a custom model that relies on proprietary software such as Netica, Matlab or Excel, the goal is to be a domain agnostic hub for a wide breadth of scientific models.
Dojo's Solution
Dojo presents a novel solution to this problem: it offers scientists access to a highly instrumented web-based terminal emulation environment where they can install their model, annotate their model’s configuration process, instruct the system on how to perform a simulation and finally identify and annotate the simulation result files and plots. Once completed, Dojo generates a Docker container of the model which allows for repeatable and reproducible model execution by ensuring a consistent compute environment.
The Dojo system itself stores expansive metadata about models and their configurations, allowing for complex and unique models to be configured via an intuitive and consistent application programming interface (API). When it comes to model execution, all models registered to Dojo are executable via a single API, regardless of their scientific domain or programming language. This innovation enables tools like Causemos to provide a unified interface for analysts to configure model simulations without the need to write a single line of code.
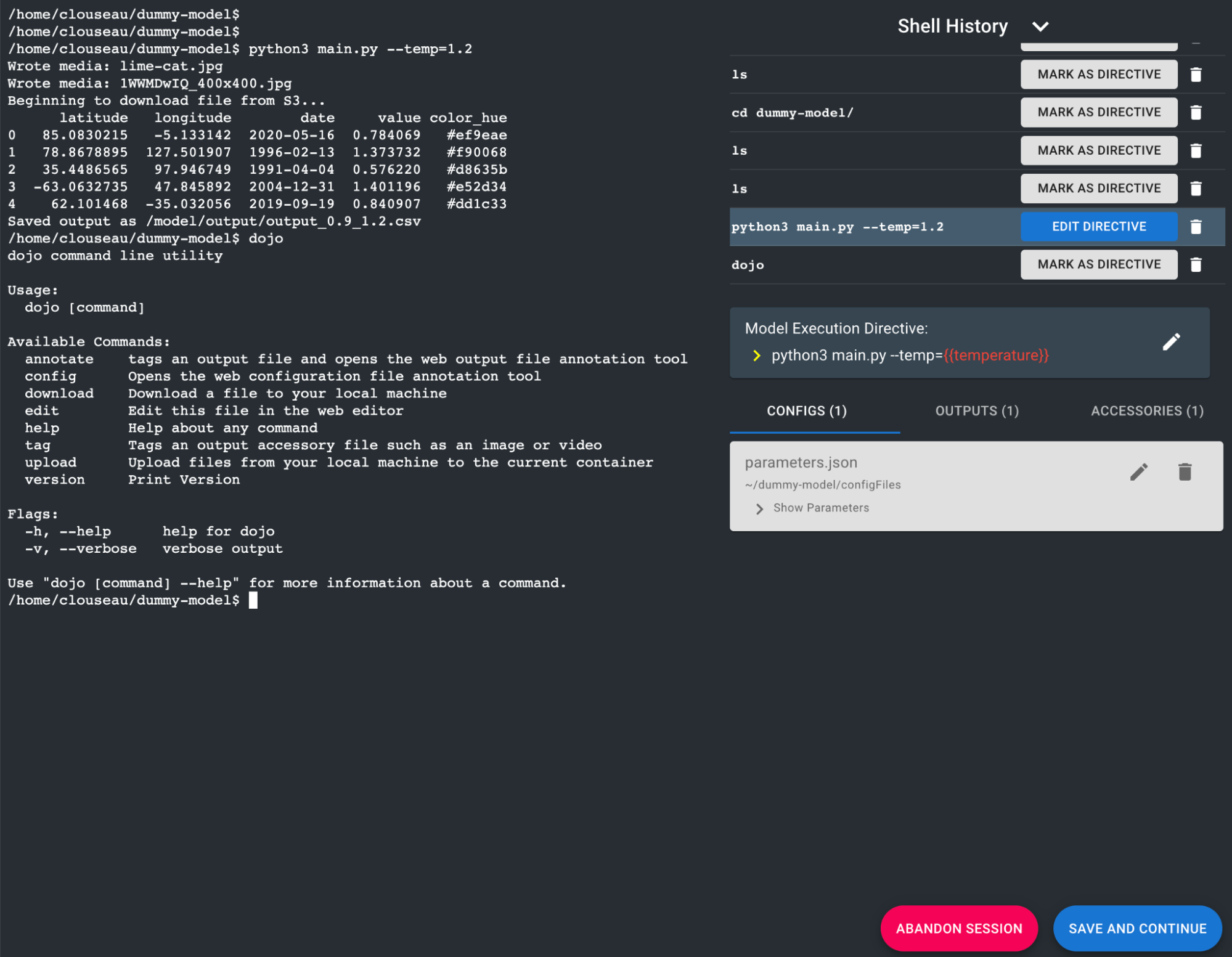
The Model Terminal Emulator
Datasets in Dojo
Dataset Registration
The key to most analytic tasks is appropriate data. For complex systems analysis this can present a major hurdle: oftentimes the data needed are in formats that are inaccessible to most analysts. For example, much climate data is produced in NetCDF format: an excellent format for compressing climate-scale data, but one that is totally inhospitable to analysts without strong programming skills.
Dojo democratizes access to data from NetCDF, GeoTIFF, Excel and CSV file formats, ingesting them into a single interface for annotation by the Dojo user. Dojo relies on AI to assess each dataset at the time it is ingested to attempt to infer key pieces of information such as how the dataset stores and references time and space. Users have the ability to mark up the dataset and enrich the inferred metadata at the feature or column level, enabling Dojo to be more than just a metadata repository; instead Dojo offers a truly comprehensive search and retrieval capability at the data feature level.
Downstream Uses
Furthermore, once a dataset is registered to Dojo it is exportable in a consistent, canonical format which facilitates downstream analysis and visualization. Data can come into Dojo in many formats and fashions, but once in Dojo it can be retrieved and utilized in a highly consistent fashion. A famous saying is that “Data scientists spend 80% of their time on data wrangling.” Dojo is purpose built to cut that number down dramatically while simultaneously exposing data in hard to access formats to non-technical decision makers and analysts. By providing a consistent data format, Dojo makes it possible for Causemos and other tools to generate ad hoc, high fidelity data visualizations and data dashboards without the need to implement custom, dataset specific code or tools.
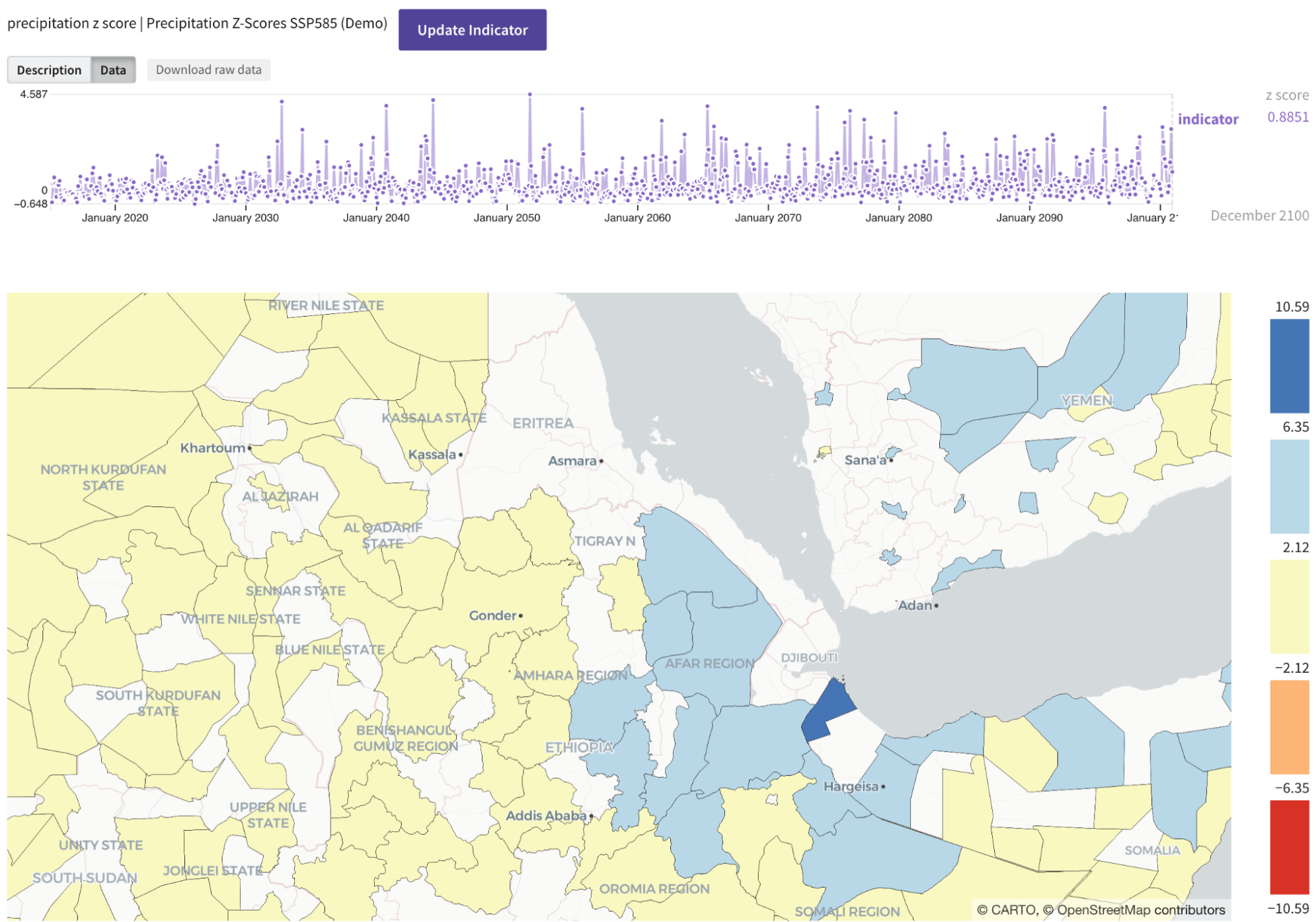
Data Visualization in Causemos
Data Modeling
Additionally, Dojo offers a no-code data modeling interface tailored for easy manipulation, visualization and analysis of climate, weather and other gridded data. The Dojo data modeler can be used to derive key insights at the intersection of diverse information from domains including climate, hydrology, population, infrastructure, agriculture, energy and more. This drag and drop interface offers users the features, power and flexibility of state of the art data science libraries without requiring the extensive programming background necessary to effectively leverage tools like Xarray or Climate Data Operators.
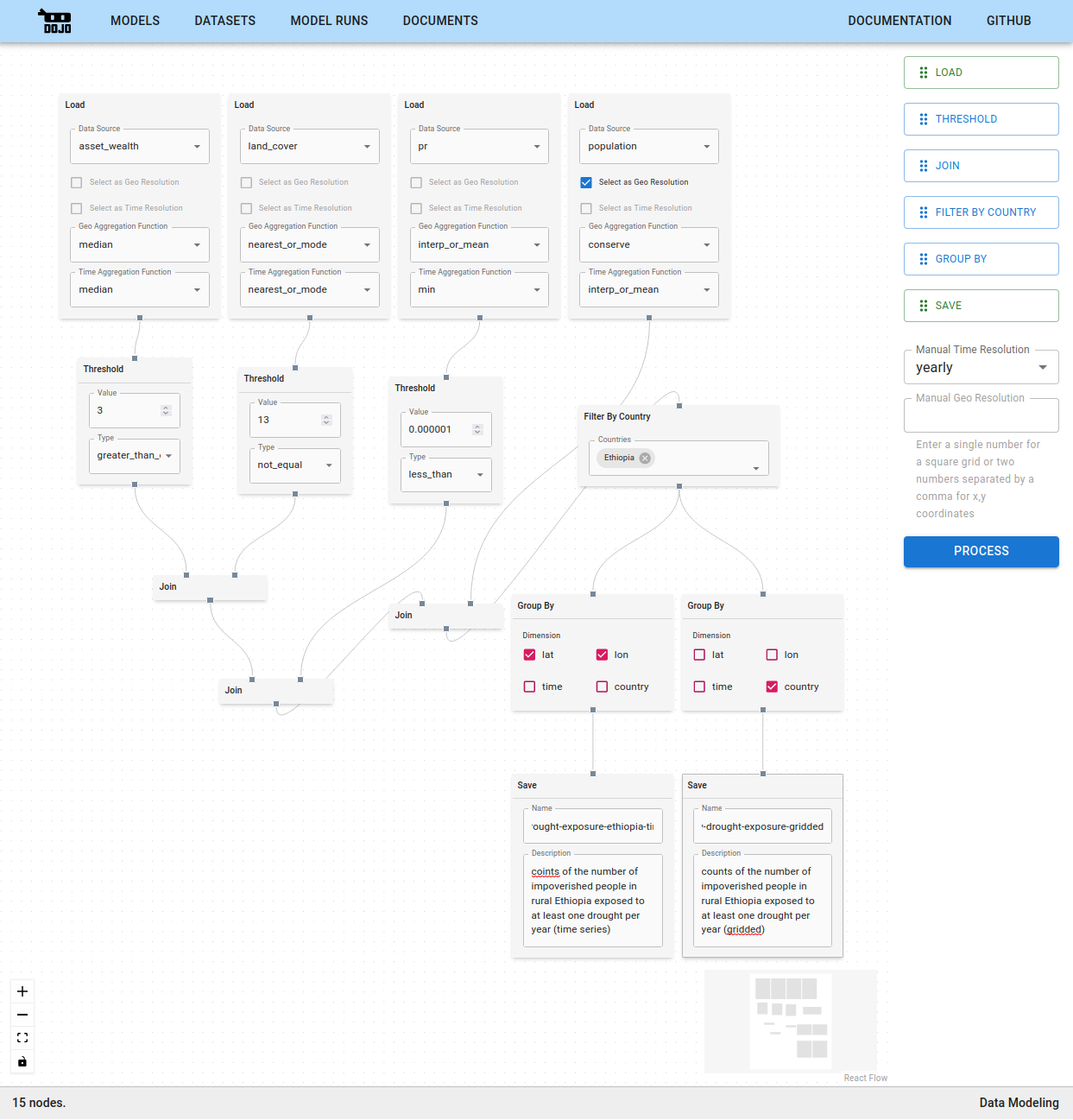
The Data Modeling Tool
Knowledge in Dojo
Document Upload and Search
Dojo provides state of the art AI supported knowledge curation and retrieval mechanisms at enterprise scale. The first step in this is an intuitive interface for the bulk upload and annotation of PDFs, PowerPoint files and Word documents. Once ingested into the system, knowledge is easily searchable through Dojo’s user interface and API.
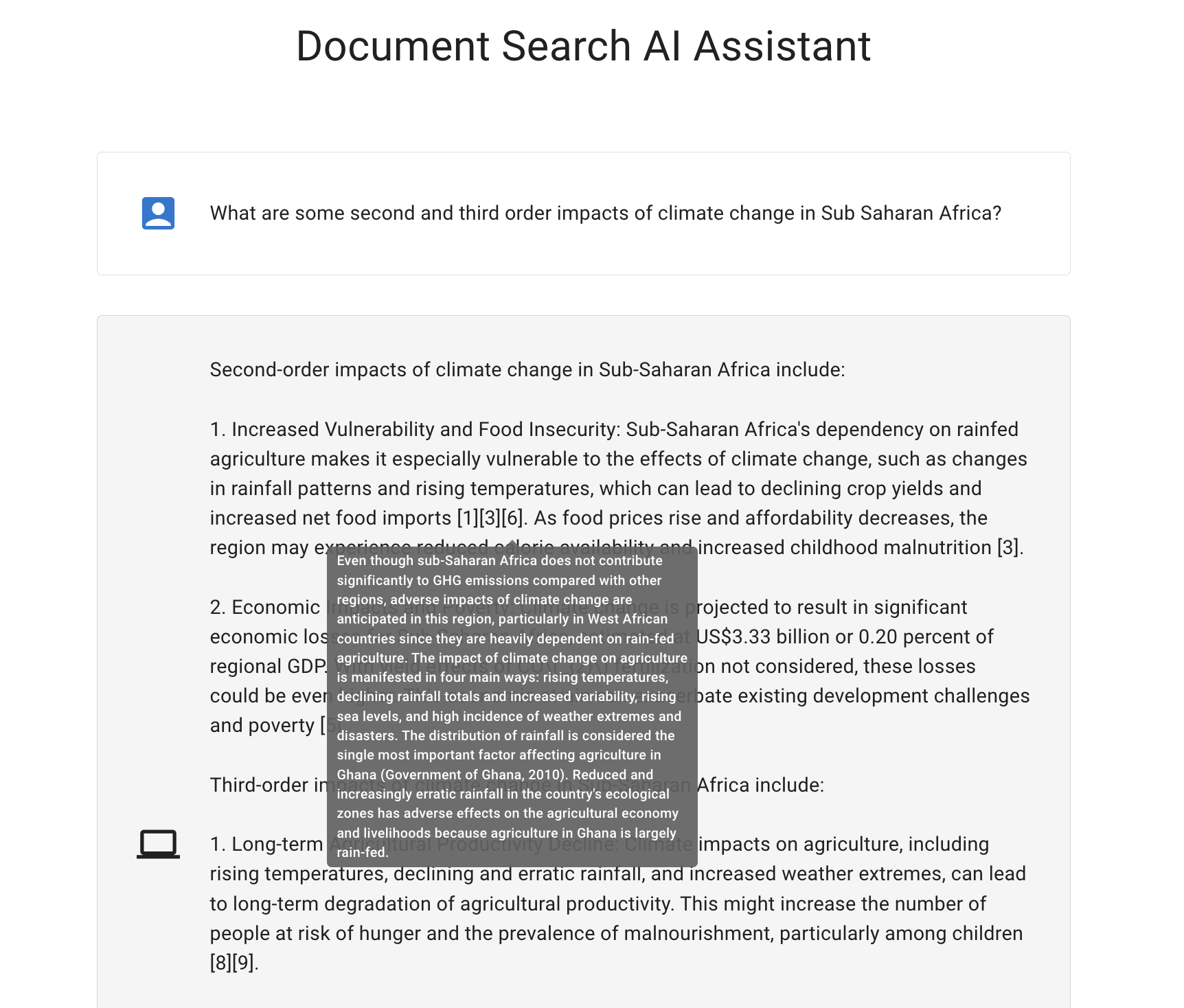
The Dojo AI Assistant
AI Assistant
Dojo offers a modern ChatGPT-like interface for question answering with results that are grounded in your organization’s knowledge base. All answers are cited, with specific references to information from the knowledge ingested into Dojo from the documents uploaded or otherwise added to the system. Users can quickly and easily open the cited documents, reports, presentations and publications to further validate and contextualize the information offered by the AI assistant.